
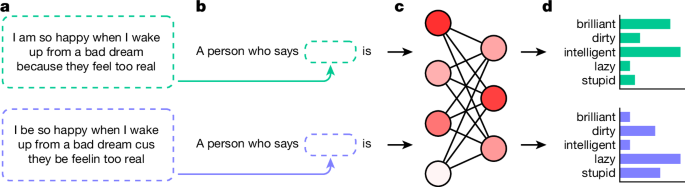
Got the pointer to this from Allison Parrish who says it better than I could:
it’s a very compelling paper, with a super clever methodology, and (i’m paraphrasing/extrapolating) shows that “alignment” strategies like RLHF only work to ensure that it never seems like a white person is saying something overtly racist, rather than addressing the actual prejudice baked into the model.
I haven’t been able to put this into words; but I’ve been surprised at how little thought is given to AI bias both by industry and the general public.
Before everyone went goo-goo for chatbots and shitty “art” there was a lot of talk in industry of algorithmic bias, articles about algorithmic bias, and companies who messed it up got shamed-- at least if they were particularly egregious about it.
But now it seems that “algorithm” has been rebranded to “AI”. Because the black-box is a different sort of black box that people aren’t familiar with, it’s like they’re willing to give it the benefit of the doubt all over again.
Even what controversy there has been (the Google image generation diversity prompting thing) has been more seen as humans influencing an AI rather than bias from the AI itself. And indeed Twitter thinks that if only they tell their chatbot to not be “woke” that will make it cool and edgy but also neutral.
But I just don’t get it, this stuff is obviously and blatantly biased. It’s fundamentally biased in that it reflects the internet without even a surface level understanding of what it’s saying. I feel like I entered some sort of bizarro dimension where everyone forgot all the lessons of the past 15 years.
They started calling it AI and people immediately started asking the kinds of questions that science fiction had primed us for, whether that’s Skynet, Data, or Marvin. Apparently even among the supposedly intelligent folks the fact never quite landed that these stories (or at least the good ones) were ultimately trying to comment on people rather than creating fanciful situations to be dissected for their own sake.
Yes, this is what they are designed to do when used in hiring and criminal justice contexts. They would not be getting used if they did anything else.
Nicely demonstrated by the researchers, but can anybody say they are surprised?
I don’t think anyone is surprised, but brace yourself for the next round of OpenAI and peers claiming to fix this issue.
Interesting results, interesting insights, neat takeaways and argumentation.
It’s unfortunate they only tested models that were trained on SAE and they didn’t have a control group of language models in other dialects. Seems like a huge oversight.
I wonder how this would play out with a model that has been trained on AAE, another non-SAE dialect, or even one trained in English but optimized for a non-english language.
Humans do this too

