Much like that comment. Can you give a better example, or express why it’s a bad example? That would bring some quality in.
Spzi
- 3 Posts
- 139 Comments
Joined 1 year ago
Cake day: June 25th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
FYI you can self-host GitLab, for example in a Docker container.

 4·7 months ago
4·7 months agoAn (intuitively) working search would be a great step ahead. It should find and show things if they exist, and only show no results if they do not. That a plethora of external tools exist to meet these basic needs shows both how much this is needed, and how much it is broken.
I also feel I have more luck finding communities if searching for ‘all’, instead of ‘communities’. Don’t make me add cryptic chars to my search to make it work. Do that for me in the background if necessary.
It’s been long since I’ve been using it, but iirc, it’s impossible or painful to search for a specific community in your subscribed list.
 5·9 months ago
5·9 months agoYou can use more debug outputs (log(…)) to narrow it down. Challenge your assumptions! If necessary, check line by line if all the variables still behave as expected. Or use a debugger if available/familiar.
This takes a few minutes tops and guarantees you to find at which line the actual behaviour diverts from your expectations. Then, you can make a more precise search. But usually the solution is obvious once you have found the precise cause.
From the title, I had a question and found the answer in the FAQ:
What’s an unconference?
An unconference is a conference in which the participants – rather than the organizers – decide which sessions happen each day and on which topics. In the many years we have been organizing unconferences, we have found that for complex subjects like the Fediverse, attendees get more value (and fun!) out of unconferences than from traditional conferences. Sounds disorganized? It did to us, too, until we actually experienced our first one. So don’t worry, it will be fine :-)
Here are some suggestions for how to prepare for an unconference.
And this is another issue which hinders discoverability. It’s nice there are tools and workarounds but their existence also signals the issue exists.
I didn’t say able to locate I said there being a list.
Are you confusing comments?
I see this in the referred comment:
having the capability to locate
While the word “list” does not appear.
But mostly I think we should try to read the message, not focus on single words.
Exactly this. It’s often about finding the right balance between technically optimal, and socially feasible (lacking the right phrase here).
The nerds brimming with technical expertise often neglect the second point.
Oh - wow! I was about to complain about how https://join-lemmy.org/ is a shining bad example in this regard, talking about server stuff right away and hiding how Lemmy actually looks until page 3, but apparently they changed that and improved it drastically. Cool, good job!
Anyways.
For collaborative projects especially, it is important to strike a balance between tech and social aspects. Making poor tech choices will put people off. But making your project less accessible will also result in less people joining. It’s crucial to find a good balance here. For many coming from the tech side, this usually means making far more concessions to the social side than intuitively feels right.
I find the plateau quite puzzling (lemmy.world, but the total looks very similar):
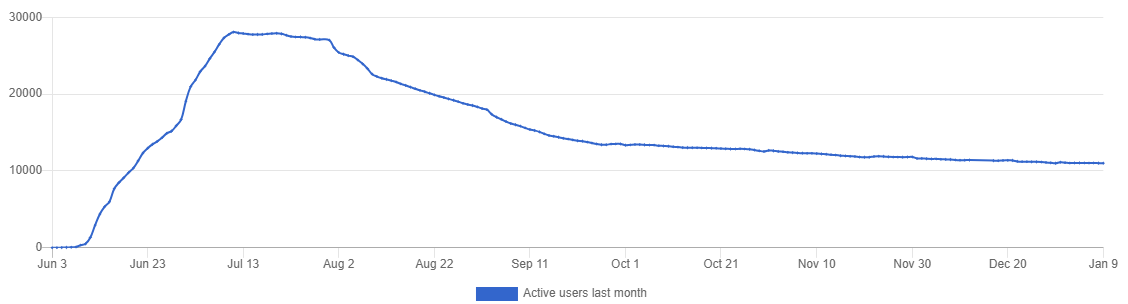
There was quite a steep increase, and then it suddenly stopped.
I would rather expect it to slow down, than to stop that abruptly.
We’re looking at a fairly large group of people making a decision to create an account on Lemmy. There are plenty of reasons to expect it to be fuzzy. Even if they all responded to one particular event in time, some would have done so immediately, others the next day, few more even later.
Yes, that’s true, but the number probably actually declined for a similar reason.
Some created multiple accounts, others tried multiple platforms. Some were happy with lemmy and stayed, others did not.
Right, it does display a karma value in the user profile page (not my own, but for others). Regardless from which instance that user is.
It does not display user karma in threads, regardless on which instance. Does your experience differ?
Reddit was using karma for a long time and people stayed. The exodus happened when reddit announced charging for using their API, and everything that came along. Karma was no significant part of that story.
When people “farm” for fake internet pointe by appealing to the oppinions of everyone else it leads to people just expressing one “right” (popular) oppinion.
We have the same result already, for several reasons. One is, we do have karma within threads.
Another is, people will get backlash for voicing the “wrong” opinion even if there is no point system. People happily reply to correct someone.
In any case, performance is just one factor. For a FOSS project to be successful long term it needs contributions from other developers and with the massive pool of Python developers there are, hopefully I’ll be getting some help soon. Also along those lines I have deliberately chosen:
to code as simply and stupidly as possible, to make it accessible to most skill levels. No complicated frameworks, fancy algorithms, or esoteric design patterns. Model View Controller, baby. No frontend build process or tool chain (vanilla JS only. No npm). Few third party dependencies, only Redis and Postgresql. Mostly.All this makes setting up an initial development environment, finding the bit you want to change and testing it out fairly quick and easy.
Sounds very wise to make it as accessible as possible. And you basically get super maintainable code as a side product!
I think that’s one of the best use cases for AI in programming; exploring other approaches.
It’s very time-consuming to play out how your codebase would look like if you had decided differently at the beginning of the project. So actually comparing different implementations is very expensive. This incentivizes people to stick to what they know works well. Maybe even more so when they have more experience, which means they really know this works very well, and they know what can go wrong otherwise.
Being able to generate code instantly helps a lot in this regard, although it still has to be checked for errors.
There’s a very naive, but working approach: Ask it how :D
Or pretend it’s a colleague, and discuss the next steps with it.
You can go further and ask it to write a specific snippet for a defined context. But as others already said, the results aren’t always satisfactory. Having a conversation about the topic, on the other hand, is pretty harmless.
Those LLMs are great fools, but I am just paranoid to use it in that manner.
Exquisite typo. I also agree to everything else you said.
You can do that when you control the frontend UI. Then, you can set up the input field for their name, applying input validation.
But I would rather not rely on telling the user, in hopes they understand and comply. If they have ways to do it wrong, they will.


{kind=link}
Hehe, good point.
I think AI bots can help with that. It’s easier now to play around with code which you could not write by yourself, and quickly explore different approaches. And while you might shy away from asking your colleagues a noob question, ChatGPT will happily elaborate.
In the end, it’s just one more tool in the box. We need to learn when and how to use it wisely.